
Data lake og datavarehus er begge mye brukt i forbindelse med lagring av store data, men de er ikke like. En data lake er et stort “basseng” med rådata, hvor formålet for dataene ennå ikke er definert. Et datavarehus er et lager for strukturerte, filtrerte data som allerede er behandlet for et bestemt formål.
De to begrepene blir ofte blandet sammen, men i realiteten er de mye mer forskjellige enn de er like. Faktisk er den eneste reelle likheten mellom dem lagring av data på høyt nivå.
Skillet mellom dem er viktig fordi de tjener ulike formål og krever forskjellige sett med øyne for å være riktig optimalisert. Mens en data lake vil fungere for ett selskap, vil et datalager passe bedre for et annet selskap.
4 viktige forskjeller mellom data lake og datavarehus
Det er flere forskjeller mellom data lake og et datavarehus. Datastrukturen, ideelle brukere, behandlingsmetoder og det overordnede formålet med dataene er nøkkel-forskjellene.
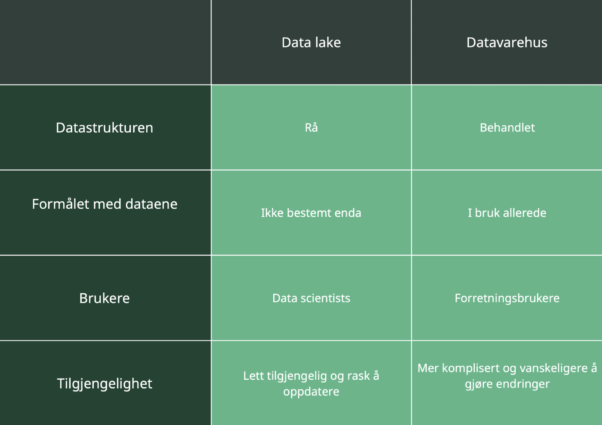
Datastruktur: rådata vs. behandlet
Rådata er data som ennå ikke er behandlet for et formål. Kanskje den største forskjellen mellom data lakes og datavarehus er den strukturen de er lagret i, nemlig rå versus behandlede data. Data lakes lagrer primært rå og ubehandlede data, mens i et datavarehus lagrer man behandlede og raffinerte data.
Derfor krever data lakes vanligvis mye større lagringskapasitet enn et datavarehus. I tillegg er rå, ubehandlet data smidige data som raskt kan analyseres for ethvert formål og er ideelle for maskinlæring. Risikoen med all den rådataen er imidlertid at data lakes noen ganger blir som en myr av data uten passende datakvalitet og styringstiltak på plass.
Datavarehus, som lagrer kun behandlede data, sparer på kostbar lagringsplass ved å ikke opprettholde data som aldri kan brukes. I tillegg kan behandlede data lett forstås av et bredere publikum.
Formål: ubestemt vs i bruk
Formålet med individuelle databrikker i en data lake er ikke fastsatt. Rådata strømmer ut i en “sjø”, noen ganger med tanke på en bestemt fremtidig bruk og noen ganger bare for å ha det. Dette betyr at data lakes er mindre organisert og har mindre filtrering av data enn i datavarehus.
Behandlede data er rådata som er blitt brukt til en spesifikk bruk. Siden datavarehus kun inneholder behandlede data, har alle dataene i et datavarehus blitt brukt til et bestemt formål i organisasjonen. Dette betyr at lagringsplass ikke blir kastet bort på data som aldri kan brukes.
Brukere: data scientists vs forretningsbrukere
Data lakes er ofte vanskelig å navigere i for de som ikke er kjent med ubehandlede data. Rå, ustrukturerte data krever vanligvis en dataviter, samt spesialiserte verktøy for å forstå og oversette dataene for spesifikk forretningsbruk.
Behandlede data brukes i diagrammer, regneark, tabeller og mer, slik at de fleste, om ikke alle, ansatte i et selskap kan lese det. Behandlede data, som de som er lagret i et datavarehus, krever bare at brukeren er kjent med emnet som er representert.
Tilgjengelighet: fleksibel vs sikker
Tilgjengelighet og brukervennlighet refererer til bruken av datalageret som en helhet, ikke dataene i lagret. Data lake arkitektur har ingen struktur og er derfor lett tilgjengelig og lett å endre. I tillegg kan eventuelle endringer som gjøres på dataene gjøres raskt siden data lakes har svært få begrensninger.
Datavarehuset er designet for å være mer strukturert. En stor fordel med datavarehusarkitektur er at behandlingen og strukturen av data gjør selve dataene lettere å tyde. Begrensningene i strukturen gjør datavarehuset vanskelig og kostbart å manipulere.
Hva er riktig for meg?
Organisasjoner trenger ofte begge deler. Data lakes oppstod ut fra et behov om å utnytte store data og dra nytte av de rå og ustrukturerte dataene for maskinlæring, men det er fortsatt behov for å lagre data i et datavarehus for analytisk bruk av forretningsbrukere. Talend gir oss en oversikt over hva som kan passe for ulike industrier:
Helsesektoren: data lakes lagrer ustrukturert informasjon
Datavarehus har blitt brukt i mange år i helsevesenet, men det har aldri vært helt vellykket. På grunn av den ustrukturerte naturen til mye av dataene i helsevesenet (legenotater, kliniske data, etc.) og behovet for sanntidsinnsikt, er datavarehus generelt ikke en ideell modell. Data lakes tillater en kombinasjon av strukturerte og ustrukturerte data, som har en tendens til å passe bedre for helseforetak.
Utdanningssektoren: data lakes tilbyr fleksible løsninger
De siste årene har verdien av stordata i utdanningsreformen blitt veldig tydelig. Data om karakterer, oppmøte og så videre, kan ikke bare hjelpe studenter som feiler å komme tilbake på riktig spor, men kan faktisk bidra til å forutsi potensielle problemer før de oppstår. Fleksible big data-løsninger har også hjulpet utdanningsinstitusjoner med å effektivisere fakturering, forbedre innsamling av penger og så videre.
Disse dataene er ofte enorme og veldig rå, så ofte har institusjoner innen utdanningssektoren størst nytte av fleksibiliteten i data lakes.
Finanssektoren: datavarehus appellerer til massene
Innenfor økonomi, så vel som andre forretningsinnstillinger, er et datavarehus ofte den beste lagringsmodellen. Det fordi denne modellen kan være strukturert for tilgang for hele selskapet i stedet for en kun datavitere. Big data har hjulpet finanssektoren med å gjøre store fremskritt, og datavarehus har vært en stor aktør i disse fremskrittene.
Transport: data lakes hjelper med prediksjoner
Mye av fordelen med en data lake ligger i evnen til å komme med prediksjoner. I transportindustrien, spesielt innen forsyningskjedestyring, kan prediksjonskapasiteten som kommer fra fleksible data i en data lake ha store fordeler. Nemlig kostnadsreduserende fordeler realisert ved å undersøke data fra skjemaer innen transportørens pipeline.