
Som vi tidligere har sett på er det en pågående debatt om man egentlig kan bruke personopplysninger til test og utvikling av it-systemer. Skal man være på den trygge siden når man gjennomfører testing av data, må man da syntetisere produksjonsdata, enten manuelt eller ved hjelp av maskinlæring. På den måten kan dataene bli et godt speilbilde av produksjonsdataene, men personopplysningene blir anonymisert og ikke på noen måte mulig å gjenskape.
Nedenfor gjennomgår vi tre forskjellige praksiser for testdata før vi gir deg vår anbefaling for hvilke metode du bør bruke.
Skarpe data
Skarpe data er de reelle dataene som befinner seg i produksjonssystemet ditt. Mange kopierer disse produksjonsdata til test og utvikling av it-systemer. Dette kan være problematisk med tanke på hvordan personopplysninger flyter gjennom systemet, og hvor vanskelig det er å holde oversikten på hvor den enkeltes personopplysninger ligger lagret, hvilket gjør sletting vanskelig.
Dette betyr også at flere personer vil få tilgang til personopplysningene, da testere og utviklere trenger tilgang for å kunne jobbe effektivt. Sikkerhetsmekanismer og “snikelogger” er også typisk kun implementert for produksjonsmiljøet, så det er vanskeligere å kontrollere hvem som snoker på hvilke data.
Vil du lære mer om maskinlærte data? Last ned vår guide til maskinlæring, analytics og dataforvaltning her.
Maskerte data
Maskerte data er data der de aller mest identifiserende feltene er tatt bort eller byttet ut, f.eks. navn og adresse. I praksis vil det nesten alltid være mulig å gjenidentifisere maskerte personer basert på andre attributter. Dette blir i teorien en bedre datahåndtering enn om man bruker skarpe data, men i praksis er det liten forskjell.
Syntetiske data
Syntetiske data er data som ikke har rot i virkeligheten, eller som er “funnet opp”. I praksis er syntetiske data ganske enkle, og innehar typisk lav variasjon og er ofte ikke dekkende for testformål. Syntetiske data tar ofte form som scripting rett inn i en database, eller de kan legges inn gjennom en testdataklient som automatiserer denne prosessen.
Les mer om syntetiske data her.
Smarte syntetiske data er syntetiske data som hermer etter de skarpe dataene ved å bruke maskinlæring for å hente ut de statistiske egenskapene til det skarpe datasettet, men uten at identifiserende informasjon blir med i prosessen. Smarte syntetiske data skiller seg fra databasescripting ved at man gjenbruker all forretnings- og valideringslogikk, så datakvaliteten blir bedre. I tillegg er dataene lettere å integrere mot konsumenter, da den fundamentalt ikke skiller seg fra skarpe data, siden det kommer inn i systemet på samme måten. Om du ønsker å skripte i databasen er det en utfordring både å lage nok data, og å lage variert nok data. I sum gjør dette at databasescripting er mye mer jobb enn det virker som i utgangspunktet. I sum er ML-løsningen en mye mer effektiv måte å lage testdata på.
Oppsummering
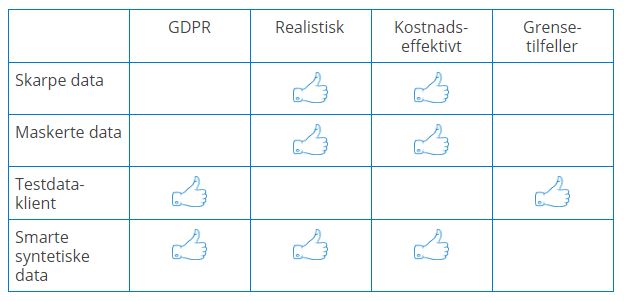
En oppsummering av de forskjellige metodene for å lage testdata finnes i tabellen under:
Vi kan hjelpe deg med syntetiske data
Som vi ser av tabellen vil smarte syntetiske data sammen med en testdataklient dekke veldig mange behov for testdata.
Vår anbefaling er derfor å bruke syntetiske testdata, og følgende kvaliteter får du da:
- GDPR-vennlige
- Realistiske
- Kostnadseffektive
Har du også behov for grensetilfeller i testdataene dine anbefaler vi en testdataklient.