
ELT-tankegangen bidrar til å øke ytelsen ved datalasting, men vedlikeholdskostnadene vil fortsatt stige i takt med størrelsen på datavarehuset. Noen datavarehus opplever å få hundrevis av hardkodede komponenter for konvertering og datalasting, og min erfaring er at vedlikeholdskostnadene spiser opp uforholdsmessig store deler av budsjettet. Grunnen til dette er at behovet for hvilke data man vil ha endrer seg over tid. Når man bruker hardkodede komponenter for datalasting må hver enkelt komponent vedlikeholdes manuelt, og kostnadene ved å gjøre gjennomgripende endringer i løsningen blir omfattende.
Generisk datavarehus
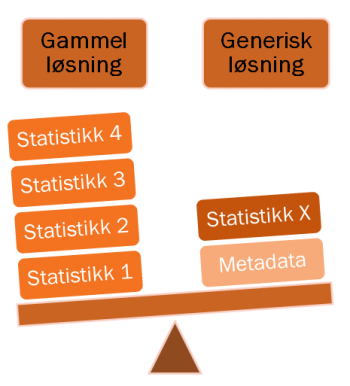
Med inspirasjon fra Bin Jiang har vi i Visma Consulting begynt å konstruere generiske datavarehus. Hovedprinsippet er at man ikke lager liknende funksjonalitet gang på gang, men lager en type funksjonalitet en gang for alle. Et eksempel er en generell komponent for datalasting i datavarehuset. Vi lager én generisk komponent som kan laste alle typer data mellom de ulike tabellene, og hvilke felter etc. som skal inngå i en last styres med en enkel metadatamodell. Dermed blir det enkelt å gjøre gjennomgripende endringer i løsningen fordi man kun trenger å endre den ene komponenten eller oppdatere metadata. Endringene kan gjøres helt uten deploy, da vi ikke benytter verktøy med sterke bindinger. På kjøpet får man også sentral logging og full sporbarhet på alle dataene i datavarehuset.
Den store styrken til generisk datavarehus
I datavarehus ønsker man ofte å laste inn nye data som likner på noe man allerede har. Som f.eks å lage nye statistikker eller rapporter. I slike situasjoner ser vi den store styrken til generisk datavarehus, fordi man ikke trenger å implementere nye komponenter. Istedenfor opprettet vi nye metadata og i løpet av få minutter er alt klart for å ta imot de nye dataene. Deploy er heller ikke nødvendig, og dermed ser vi en stor forbedring i feilrettingstid og generell time to market.
Dersom vedlikeholdskostnadene til datavarehuset øker i takt med størrelsen bør man vurdere å følge prinsippene til et generisk datavarehus.
Vi hjelper deg gjerne med å realisere datavarehuset på en best mulig måte. Les mer om hvordan!